
A chatbot to talk about the real stuff [Ep. 1]
Have you ever wondered how it is to talk to an AI that can answer to precise questions about life? Well I wonder too, and as I wanted an answer, I tried to code it myself. What I did instead, is to translate into tensorflow what is defined as a grounded chatbot, that was originally written in pytorch for the ParlAI library. If you are interested, you can find my tensorflow implementation here.
The original paper Wizard of Wikipedia: Knowledge-Powered Conversational agents, introduces a dataset where two humans were asked to play one the role of a Wikipedia expert (the Wizard), the other the role of an apprentice (the Apprentice). They are meant to have an open ended dialogue, where the Wizard has access to Wikipedia articles to be able to give more accurate replies. The goal is to have an AI learning to play the role of the expert. So, they introduce two baseline architectures based on Transformer, that they name End2End and Two-Stage.
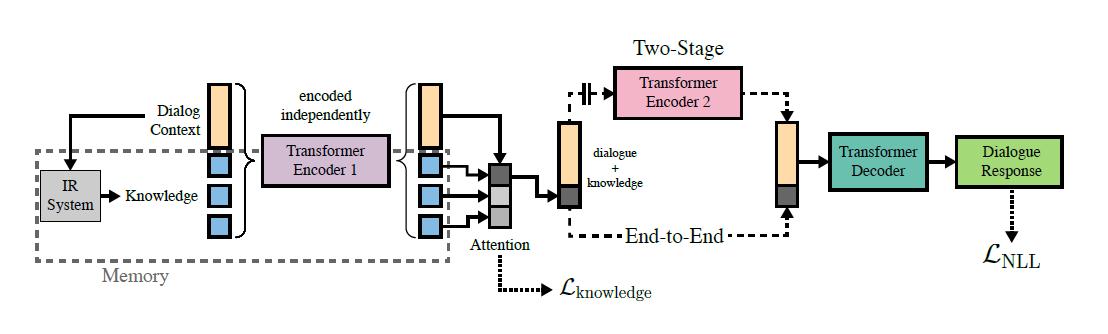
We only translated into tensorflow the End2End generative variant. The best performances we achieve are a validation perplexity of 11.3 (the lower the merrier) and a validation F1 of 35.7% (the higher the merrier), which is a small improvement over the results reported by the original work, table 4, of a test perplexity of 23.1 and test F1 of 35.5%. In coming iterations of this post I will compare test results on test results, but I didn’t want to overfit on the test set, so I didn’t record it. The small improvements are probably due to the choice of initializers and the custom knowledge dropout that we implemented since we did not find the original pytorch implementation.
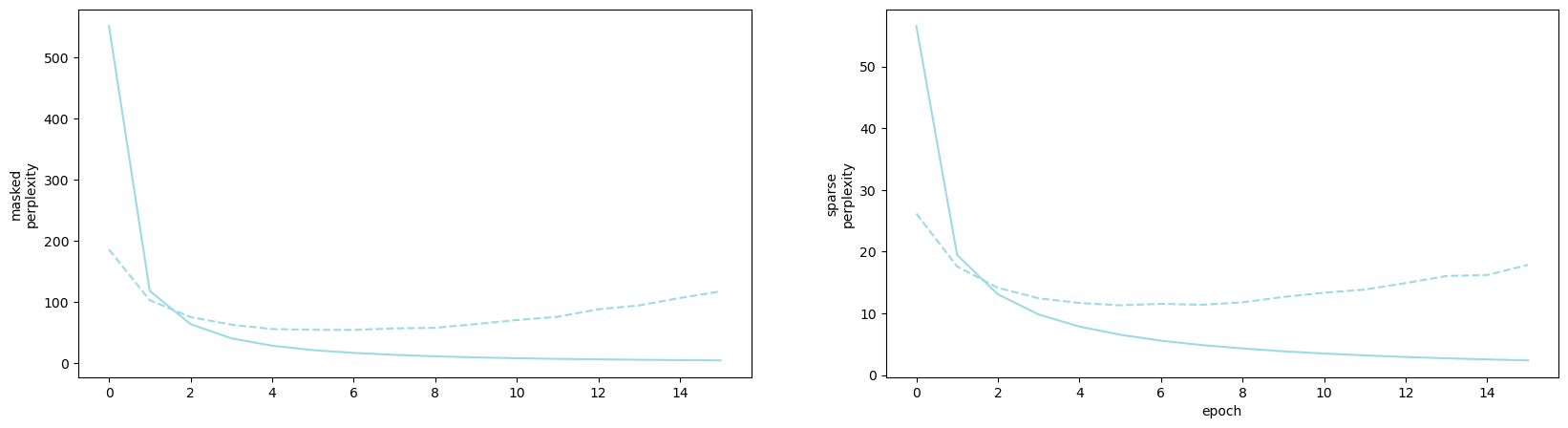
A small ambiguity remains, since we optimized over a variant of perplexity that doesn’t take into account masked symbols, see padding symbol. The performance is a bit worse on validation masked perplexity, a minimum of 54.0, but the original pytorch code, doesn’t seem to use a masked perplexity. Here the training curves with some beautiful overfitting going on:
More details to come, and some in the second episode! I plan to improve this post little by little, so I can showcase some tricks that I’ve learned, and hopefully I can make it more didactical with further iterations. I wrote the code to be able to make small variants that I want to publish, but since now I have the baseline code that I wrote from scratch and gives slightly better accuracy, kind of proud to show.